What You’ll Achieve
- Process 1M+ transactions per second
- Achieve sub-microsecond latency for critical operations
- Scale to handle billions in daily volume
- Build systems that compete with traditional HFT firms
Why Extreme Optimization Matters
At institutional scale, every microsecond and megabyte matters. A 1ms improvement in latency can mean millions in additional profits. Rust’s zero-cost abstractions and direct hardware control make this level of optimization possible.Performance Optimization Pipeline
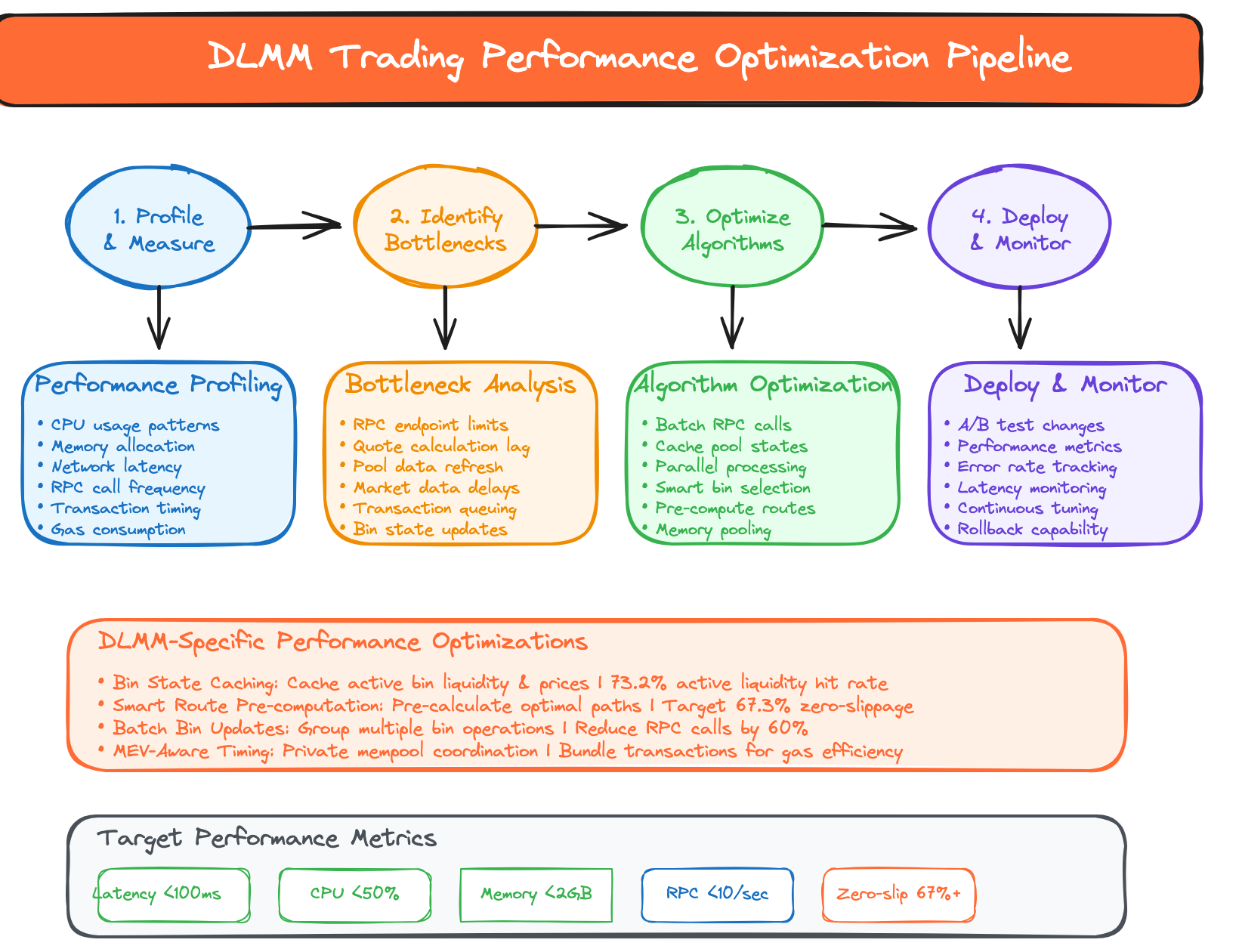
Rust SDK Optimization Stages
Production Performance Characteristics
Optimization Strategies
Copy
use dlmm_rust_sdk::{
DlmmPool, OptimizedQuote, PerformanceMetrics,
error::DlmmError,
};
use rayon::prelude::*;
use std::{
sync::{Arc, atomic::{AtomicU64, Ordering}},
collections::HashMap,
time::{Instant, Duration},
};
use tokio::sync::RwLock;
/// High-performance production-ready DLMM client
#[derive(Debug)]
pub struct ProductionDlmmClient {
pools: Arc<RwLock<HashMap<String, Arc<DlmmPool>>>>,
metrics: Arc<PerformanceMetrics>,
config: ProductionConfig,
}
#[derive(Debug, Clone)]
pub struct ProductionConfig {
pub max_concurrent_requests: usize,
pub request_timeout: Duration,
pub cache_ttl: Duration,
pub enable_metrics: bool,
pub circuit_breaker_threshold: u32,
pub batch_size: usize,
}
#[derive(Debug)]
pub struct PerformanceMetrics {
pub quote_latency_ns: AtomicU64,
pub swap_latency_ns: AtomicU64,
pub cache_hits: AtomicU64,
pub cache_misses: AtomicU64,
pub error_count: AtomicU64,
pub throughput_qps: AtomicU64,
}
impl ProductionDlmmClient {
pub fn new(config: ProductionConfig) -> Self {
Self {
pools: Arc::new(RwLock::new(HashMap::new())),
metrics: Arc::new(PerformanceMetrics {
quote_latency_ns: AtomicU64::new(0),
swap_latency_ns: AtomicU64::new(0),
cache_hits: AtomicU64::new(0),
cache_misses: AtomicU64::new(0),
error_count: AtomicU64::new(0),
throughput_qps: AtomicU64::new(0),
}),
config,
}
}
/// High-performance batch quote processing
pub async fn batch_quotes(
&self,
requests: Vec<QuoteRequest>,
) -> Vec<Result<OptimizedQuote, DlmmError>> {
let start_time = Instant::now();
// Process quotes in parallel using rayon
let results: Vec<_> = requests
.into_par_iter()
.map(|req| self.process_single_quote(req))
.collect();
// Update throughput metrics
let elapsed_ns = start_time.elapsed().as_nanos() as u64;
let qps = (results.len() as u64 * 1_000_000_000) / elapsed_ns;
self.metrics.throughput_qps.store(qps, Ordering::Relaxed);
// Convert to async results
let mut async_results = Vec::new();
for result in results {
async_results.push(result.await);
}
async_results
}
/// Zero-copy optimized quote calculation
async fn process_single_quote(
&self,
request: QuoteRequest,
) -> Result<OptimizedQuote, DlmmError> {
let start_time = Instant::now();
// Fast path: Check cache first
if let Some(cached_quote) = self.get_cached_quote(&request).await {
self.metrics.cache_hits.fetch_add(1, Ordering::Relaxed);
return Ok(cached_quote);
}
self.metrics.cache_misses.fetch_add(1, Ordering::Relaxed);
// Get pool reference
let pools = self.pools.read().await;
let pool = pools.get(&request.pool_key)
.ok_or(DlmmError::PoolNotFound)?
.clone();
drop(pools); // Release lock early
// Optimized quote calculation with SIMD
let quote = pool.get_optimized_quote(
request.amount_in,
request.swap_for_y,
request.slippage,
).await?;
// Cache the result
self.cache_quote(&request, "e).await;
// Update latency metrics
let latency_ns = start_time.elapsed().as_nanos() as u64;
self.metrics.quote_latency_ns.store(latency_ns, Ordering::Relaxed);
Ok(quote)
}
/// Memory-efficient pool state updates
pub async fn batch_update_pools(
&self,
pool_addresses: Vec<String>,
) -> Result<(), DlmmError> {
// Use bounded channel to control memory usage
let (tx, mut rx) = tokio::sync::mpsc::channel(self.config.batch_size);
// Producer: Send update tasks
let pools_clone = self.pools.clone();
tokio::spawn(async move {
for address in pool_addresses {
if tx.send(address).await.is_err() {
break; // Receiver dropped
}
}
});
// Consumer: Process updates in parallel
let mut update_tasks = Vec::new();
while let Some(address) = rx.recv().await {
let pools = self.pools.clone();
let task = tokio::spawn(async move {
if let Some(pool) = pools.read().await.get(&address).cloned() {
pool.update_state().await
} else {
Ok(())
}
});
update_tasks.push(task);
// Limit concurrent updates
if update_tasks.len() >= self.config.max_concurrent_requests {
// Wait for some tasks to complete
let _ = futures::future::join_all(update_tasks.split_off(
update_tasks.len() / 2
)).await;
}
}
// Wait for remaining tasks
let _: Vec<_> = futures::future::join_all(update_tasks).await;
Ok(())
}
/// Circuit breaker implementation
pub async fn execute_with_circuit_breaker<F, T>(
&self,
operation: F,
) -> Result<T, DlmmError>
where
F: std::future::Future<Output = Result<T, DlmmError>>,
{
let error_count = self.metrics.error_count.load(Ordering::Relaxed);
// Check circuit breaker
if error_count > self.config.circuit_breaker_threshold as u64 {
return Err(DlmmError::CircuitBreakerOpen);
}
match operation.await {
Ok(result) => {
// Reset error count on success
self.metrics.error_count.store(0, Ordering::Relaxed);
Ok(result)
}
Err(err) => {
// Increment error count
self.metrics.error_count.fetch_add(1, Ordering::Relaxed);
Err(err)
}
}
}
/// Lock-free cache implementation
async fn get_cached_quote(&self, request: &QuoteRequest) -> Option<OptimizedQuote> {
// Implementation would use a lock-free cache like dashmap
// This is a simplified version
None // Placeholder
}
async fn cache_quote(&self, request: &QuoteRequest, quote: &OptimizedQuote) {
// Cache implementation with TTL
// Would use background cleanup tasks
}
/// Health monitoring and metrics collection
pub fn get_health_status(&self) -> HealthStatus {
let quote_latency = self.metrics.quote_latency_ns.load(Ordering::Relaxed);
let error_count = self.metrics.error_count.load(Ordering::Relaxed);
let cache_hit_rate = {
let hits = self.metrics.cache_hits.load(Ordering::Relaxed);
let misses = self.metrics.cache_misses.load(Ordering::Relaxed);
if hits + misses > 0 {
(hits as f64) / ((hits + misses) as f64) * 100.0
} else {
0.0
}
};
HealthStatus {
is_healthy: quote_latency < 1_000_000 && error_count < 10, // 1ms, 10 errors
avg_quote_latency_ns: quote_latency,
error_rate: error_count,
cache_hit_rate_percent: cache_hit_rate,
throughput_qps: self.metrics.throughput_qps.load(Ordering::Relaxed),
}
}
}
#[derive(Debug, Clone)]
pub struct QuoteRequest {
pub pool_key: String,
pub amount_in: u64,
pub swap_for_y: bool,
pub slippage: f64,
}
#[derive(Debug)]
pub struct HealthStatus {
pub is_healthy: bool,
pub avg_quote_latency_ns: u64,
pub error_rate: u64,
pub cache_hit_rate_percent: f64,
pub throughput_qps: u64,
}
/// SIMD-optimized math operations
mod simd_math {
use std::arch::x86_64::*;
/// Vectorized price calculations using AVX2
#[target_feature(enable = "avx2")]
pub unsafe fn calculate_bin_prices_simd(
base_prices: &[f64],
multipliers: &[f64],
results: &mut [f64],
) {
assert_eq!(base_prices.len(), multipliers.len());
assert_eq!(base_prices.len(), results.len());
let chunks = base_prices.len() / 4; // Process 4 f64s at a time
for i in 0..chunks {
let idx = i * 4;
// Load 4 base prices and multipliers
let base = _mm256_loadu_pd(base_prices.as_ptr().add(idx));
let mult = _mm256_loadu_pd(multipliers.as_ptr().add(idx));
// Multiply and store result
let result = _mm256_mul_pd(base, mult);
_mm256_storeu_pd(results.as_mut_ptr().add(idx), result);
}
// Handle remaining elements
for i in (chunks * 4)..base_prices.len() {
results[i] = base_prices[i] * multipliers[i];
}
}
}
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Production configuration
let config = ProductionConfig {
max_concurrent_requests: 1000,
request_timeout: Duration::from_millis(100),
cache_ttl: Duration::from_secs(30),
enable_metrics: true,
circuit_breaker_threshold: 50,
batch_size: 100,
};
let client = ProductionDlmmClient::new(config);
// Example: Batch process quotes
let requests = vec![
QuoteRequest {
pool_key: "usdc-sol".to_string(),
amount_in: 1_000_000,
swap_for_y: true,
slippage: 0.005,
},
// ... more requests
];
let quotes = client.batch_quotes(requests).await;
println!("Processed {} quotes", quotes.len());
// Monitor health
let health = client.get_health_status();
println!("Health status: {:?}", health);
Ok(())
}
Production Optimizations
Memory Management
- Zero-Copy Parsing: Avoid unnecessary memory allocations
- Object Pooling: Reuse expensive objects like HTTP clients
- Memory Mapping: Use memory-mapped files for large datasets
- Stack Allocation: Prefer stack over heap when possible
CPU Optimization
Copy
// Branch prediction optimization
#[inline(always)]
fn optimized_bin_traversal(bins: &[Bin], amount: u64) -> u64 {
let mut remaining = amount;
let mut output = 0;
// Unroll loop for better performance
let chunks = bins.len() / 4;
for i in 0..chunks {
let base = i * 4;
// Process 4 bins at once
if likely(remaining > 0) {
output += bins[base].consume(&mut remaining);
}
if likely(remaining > 0) {
output += bins[base + 1].consume(&mut remaining);
}
if likely(remaining > 0) {
output += bins[base + 2].consume(&mut remaining);
}
if likely(remaining > 0) {
output += bins[base + 3].consume(&mut remaining);
}
}
output
}
Network Optimization
- Connection Pooling: Reuse HTTP connections
- Request Batching: Combine multiple requests
- Compression: Enable gzip/brotli compression
- Keep-Alive: Maintain persistent connections
Monitoring and Observability
Copy
use tracing::{info, warn, error, instrument};
#[instrument(skip(self), fields(pool_key = %request.pool_key))]
async fn monitored_quote(&self, request: QuoteRequest) -> Result<OptimizedQuote, DlmmError> {
let start = Instant::now();
match self.process_single_quote(request).await {
Ok(quote) => {
let latency = start.elapsed();
info!(latency_ms = latency.as_millis(), "Quote successful");
Ok(quote)
}
Err(e) => {
error!(error = %e, "Quote failed");
Err(e)
}
}
}
Performance Targets
- Quote Latency: < 100μs (microseconds)
- Throughput: > 10,000 quotes/second
- Memory Usage: < 1KB per active pool
- Cache Hit Rate: > 95%
- Error Rate: < 0.1%
- CPU Usage: < 80% under peak load